
Takahashi
Section1
はじめに(背景と目的)
弊社で開発したDQN (Deep Q Network)アルゴリズムを「陣取りゲーム」を用いて検証した 。
本取り組みで用いた「陣取りゲーム」について
下図のように得点が表示されたフィールドを使用し、獲得したマスの数 、 囲ったエリアにより得点を得ることができる。
最終的には獲得合計点が高いプレイヤーの勝利となる。
詳細なルールは以下の通り。
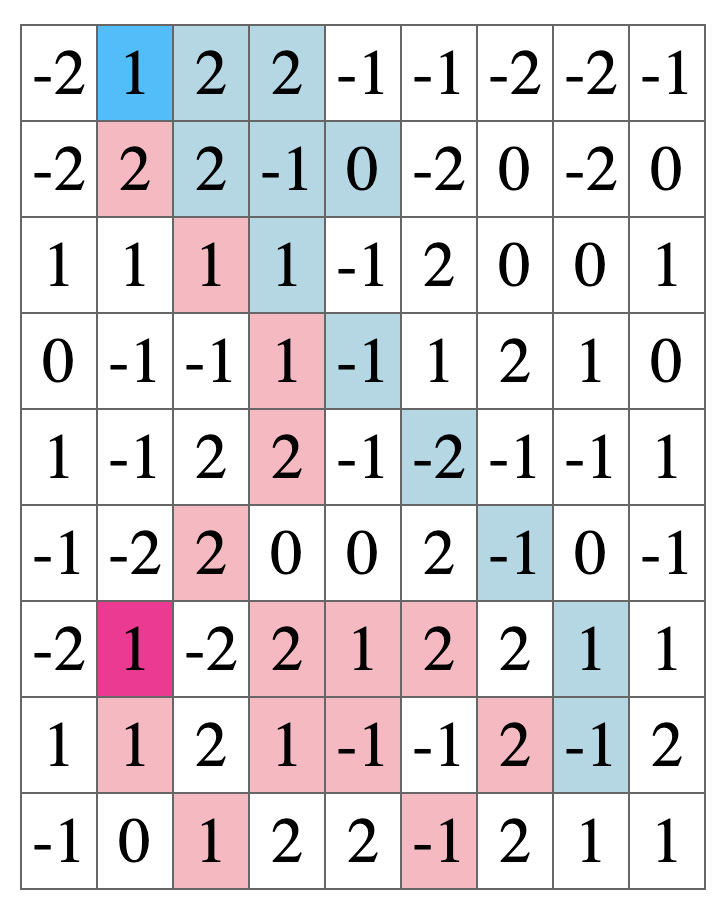
陣取りゲームのルール
競技フィールドについて
- フィールドサイズは,縦・横が8~12マスのランダムで決定される。
- 初期位置はランダムに決定され,フィールドのおおよそ対角線上に原点対称な位置で配置される。
- 操作できるコマ(エージェント)は,各チーム1体ずつ。
- フィールドの各マスには、 -2~2 の整数値が割り当てられる。
- そして,1ターンごとに各マスのポイントはランダムに変化する。
試合の進行
- フィールドサイズは、縦・横が8~12マスのランダムで決定される。
- ターン数は 30~45の間でランダムに決定される。全ターン終了することでゲームは終了する。
- エージェントが取れる行動は、「移動」、「タイル除去」、「停留」の3つ。
- 「移動」は、周囲8方向の1マスに移動できる。
相手チームのタイルが置かれたマスには移動できないが、移動したい場合はタイル除去で相手チームのタイルを取り除いた後に次のターンでマスへ移動しなければならない。 - 「タイル除去」は、8方向のいずれかの方向に隣接する相手チーム自チームのタイルを除去できる。
相手チームのエージェントがいるマスをタイル除去に指定できるが、そのエージェントが停留を選択すると除去できない。 - 「停留」は、何もせずに現在のいるマスに停留できる。
- 「移動」は、周囲8方向の1マスに移動できる。
得点の計算
「タイルポイント」、「領域ポイント」、「合計点」がある。
- タイルポイントとは、自チームが置いたタイルのポイントの合計。
- 領域ポイントとは、自チームのタイルによって囲まれた領域のマスの合計。
- 合計ポイントとは、タイルポイントと領域ポイントの合計。
勝敗判定
以下の優先度で勝敗が決定する。
- タイルポイントと領域ポイントの「合計ポイントが大きい方」のチーム
- 合計ポイントが等しい場合、「タイルポイントが大きい方」のチーム
- 合計ポイントとタイルポイントが等しい場合、引き分け。
Section2
開発ソース
使用言語
python3 : 3.6.9
go-lang : 1.10.4
開発機材
MacBook Pro (2017) : macOS Catalina ver.10.15.4
-> Prosessor : 2.3 GHz Dual-Core Intel Core i5
-> Memory : 16 GB 2133 MHz LPDDR3
なお、プログラムの実行はdockerで行い、コンテナではUbuntu 18.04.4 LTS を使用した。
学習の流れ
EPOCHS, NUMBER_OF_SELFPLAY, NUMBER_OF_SETS は整数とし、それぞれ学習の繰り返し回数, 評価の繰り返し回数, これらを繰り返すセット数を表す。
以下に図として示す。
学習のフェーズでは、学習を伴いながら試合をEPOCHS回行う。
評価のフェーズでは、学習をせずNUMBER_OF_SELFPLAY回試合を行い学習したAIの行動等を評価する。
学習の指標となる値
学習を行う際,学習済みモデルと実際に戦って考察することも必要だが,それ以外に学習を評価する指標として以下を設ける。
Loss
学習の際発生するLoss(損失)である。今回は,各学習フェーズで得られたLossを平均したものを扱う。
Reward
学習の際獲得するRewardである。この値によって,モデルは選択した行動が正しいのか間違っているのかを判別し学習する。
Code
これはAIが行動を選択したときに,その行動が先に書いたルールを満たすように選択されたかどうかを表すものである。1から5までの整数をとり,それぞれの意味は以下の通りである。
- out of field、つまりフィールドの範囲外に対して行動を選択したことを表す。
- no panel、つまり相手のタイルもしくは自分のタイルがないマスに対して「タイル除去」の選択をしたことを表す。
- is panel、つまり相手のタイルがあるマスに対して「移動」の選択をしたことを表す。
- is user、つまり相手エージェントがいるマスに対して「移動」もしくは「タイル除去」を選択したことを表す。
- no plobrem、つまり正しい行動をしたことを表す。
また、以下は評価フェーズで使用する指標である。
・remove(パネル除去)、move(移動)、stay(停滞)の数各試合でとった行動の種類である
・totalpoint 試合で取得したポイントの合計点。今回は各フェーズで得られたポイントを平均したものを扱う。
検証1
学習時の設定を以下に示す。
学習の設定
フィールドの設定
ランダム要素として 、 1試合のターン数、フィールドサイズ(縦 、 横)を毎試合ランダムに決定する。
これはそれぞれ、区間が[15,30],[4,8],[4,8]である一様分布から独立に得られる。
特徴量設計
features = [turn, now_turn, length, width, a_pos, b_pos,around_point,around_tile,point]
ここで, ‘turn’ ゲームの総ターン数(int),
‘now_turn’ 現在のターン数(int),
‘length’ フィールドのタテのサイズ(int),
‘width’ フィールドのヨコのサイズ(int),
‘a_pos’ 現在のagentの位置(int),
‘b_pos’ 対戦相手の位置(int),
‘around_point’ 自分の周囲8方向と現在の位置のタイルポイント(int 9),
‘around_tile’ 自分の周囲8方向に配置されているタイル(int 9),
‘point’ タイルポイント,(int * 3).
featuresの長さは27である。
報酬設計
報酬の計算式を以下のように定義する 。
ここで、
\[reward:=\frac{\text { fac } 1+\text { fac } 2+\text { fac } 3}{3}\]
を表し、
をとる。
このように設計した理由としては、(fac1により)ルールに基づく学習をさせる、(fac2により)別のマスに移動してタイルポイントを稼ぐ、(fac3により)大きな得点源となるエリアポイントをとることを学習させる、ことである。
学習時の対戦相手
学習の際はルールベースに基づく対戦相手を設定せず、未学習同士のモデルを戦わせ学習を進める。
評価時の対戦相手
初回は同じものを戦わせる。2回目以降は、それまでの学習で最もLossの中央値が小さいモデルを対戦相手と設定する。
学習回数
EPOCHS = 100,
NUMBER_OF_SELFPLAY = 20,
NUMBER_OF_SETS = 100
学習結果
Lossの推移
NUMBER_OF_SETS が30までの各評価フェーズでのLossを平均したものを表示する。ここまではLossが減少しているのがわかる。
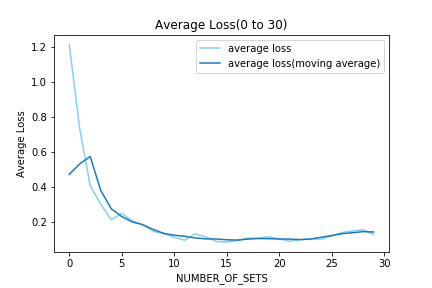
次にNUMBER_OF_SETS が80までの各評価フェーズでのLossを平均したものを表示する。40を超えたあたりからLossが増大し始めた。
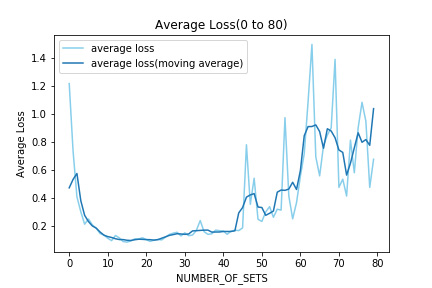
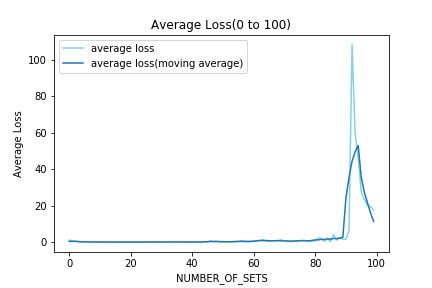
最後にNUMBER_OF_SETS が100までの各評価フェーズでのLossを平均したものを表示する.Lossの増大は収まらず、一時は大きい値をとった。
急なLossの増大によってReward等がどのように変化するのかを以下で観察する。
Rewardの評価
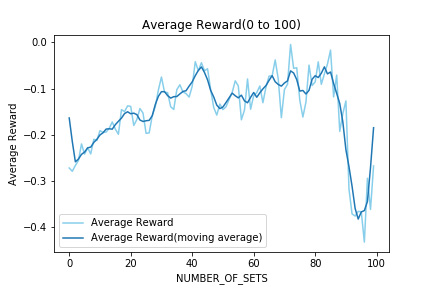
NUMBER_OF_SETS が100までの各評価フェーズでのRewardを平均したものを表示する。
先に示したLossのグラフで90を超えたあたりからLossが増大したが、Rewardに関してはその点を境に大きく減少してしまった。つまり、Lossの増大によってRewardの増加が妨げられたと考えられる。
また、全体を通して獲得したRewardの平均が0を超えることがなく、報酬設計周りの課題もあると考えられる。
しかし一度Rewardが減少してから再び増加しているので、学習回数をさらに増やした場合にどのようになるのかを検証する必要がある。
AIが陣取りゲームのルールを学習したか
この先に示す結果は評価フェーズで得られたデータである。つまり、行動の選択は全て学習済みAIが行ったものである。
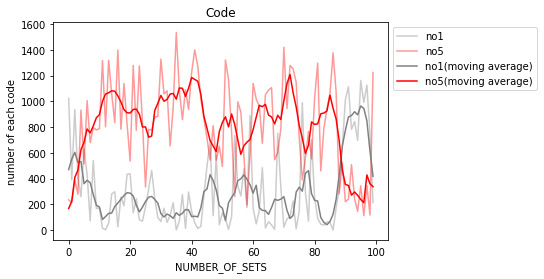
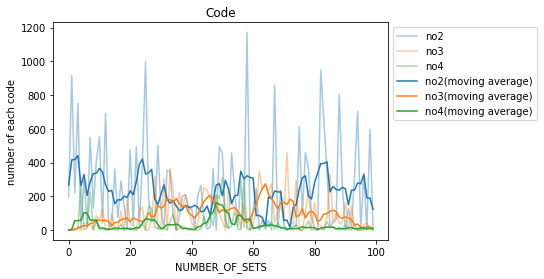
視認性を高めるため、no5(正しい行動),no1(ルール違反な行動)とそれ以外に分けた。
各々の移動平均について、全体的に見れば学習を重ねるにつれてno5は増え、no1は減っているといえるが、やはり先に述べた’Lossの増大’の部分を境にその傾向も変化している。
この項目で望む結果としては、少なくともno1,no2をとる回数が0に収束することである。
今回の実行結果だと、どの項目でもまだ大きく増減していることからさらに学習回数を重ねて観察する必要があると考えられる。
さらに、パネル除去,移動,停滞を選択した回数を見てみる。各フェーズにおいて実施した試合数(20)で平均を取った。
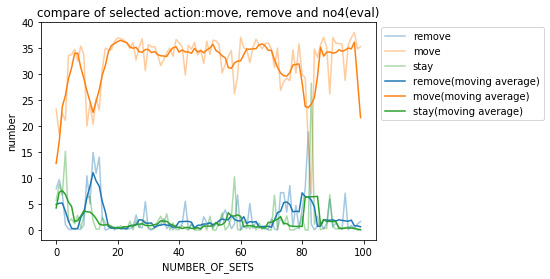
各々の移動平均について、パネル除去、停滞と比べ移動を選択していることがわかる。この結果から報酬(fac2)による効果が出ていると言える。
しかし、先のCodeに関する結果から、空いているマスに移動する・フィールドの範囲内で移動する、ということができていないと言え、完璧な報酬設計ではないといえる。
取得ポイント
次に評価フェーズで学習済みAIが取得したポイントをプロットする 。
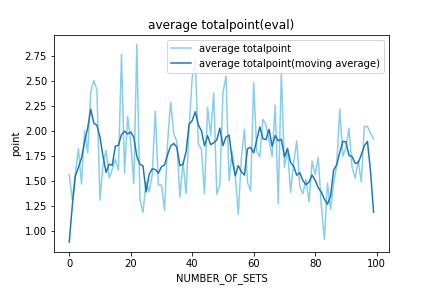
これは各評価フェーズの各ゲームで取得した(最終)ポイントの平均を表す。
この結果から、各試合で取得できるポイントが少なく、さらに学習を重ねるに つれて獲得ポイントも減少傾向にあることがわかる。
先のCode、選択した行動に関する結果から併せて考えると、得点を多くとって試合に勝つということが学習できていないと考えられる。
学習済みモデルの挙動
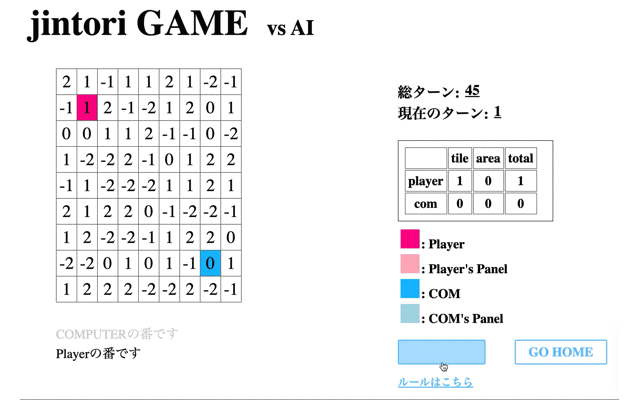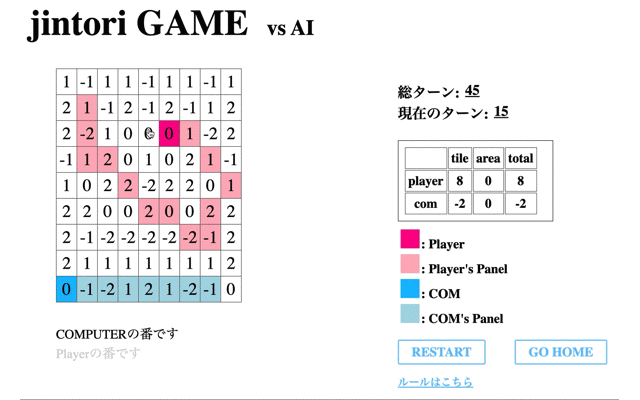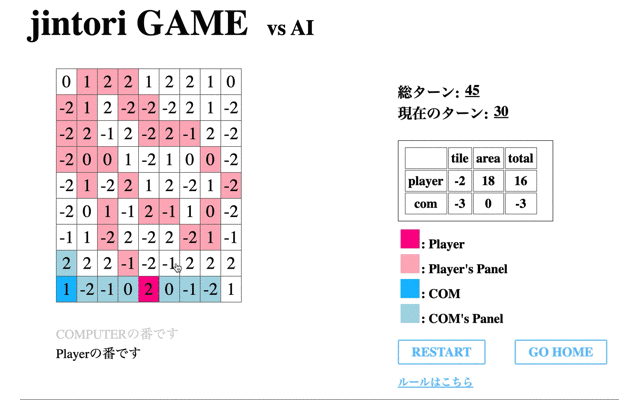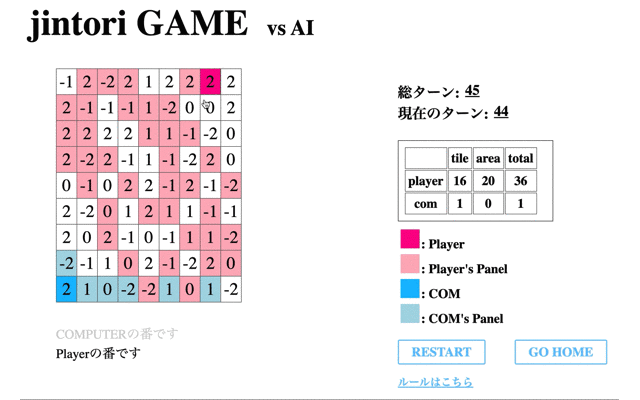
次に学習させたモデルの挙動を表示する。はじめに、1回の学習フェーズを終えたモデルの挙動を表示する。
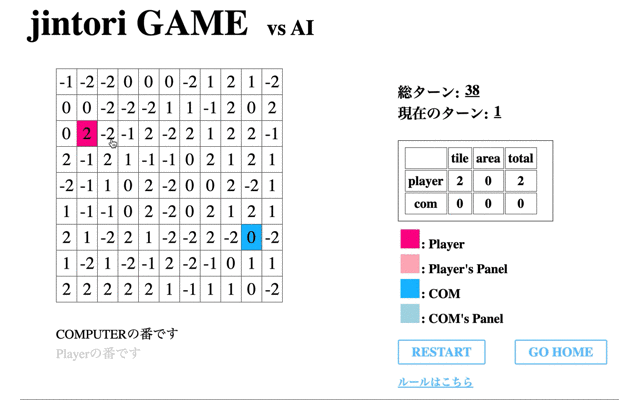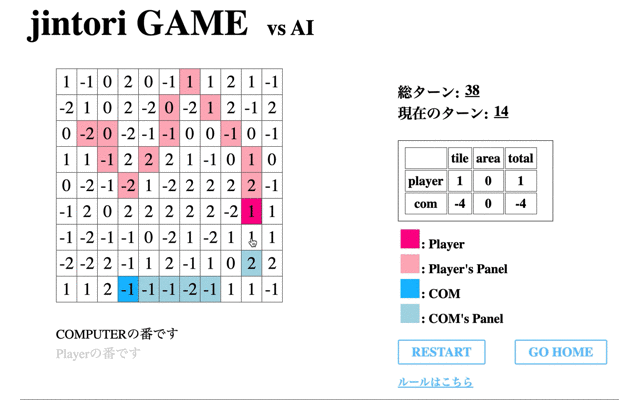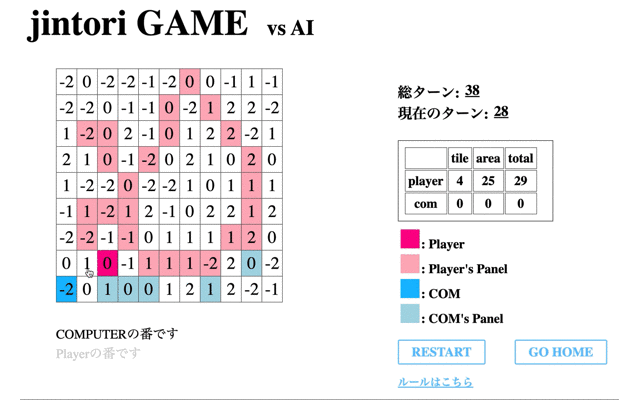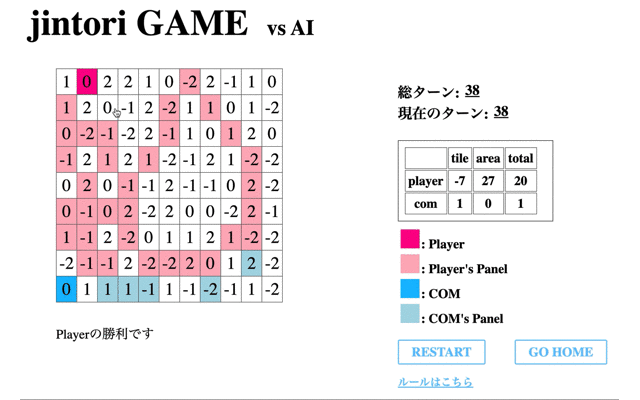
赤のタイルが私が操作したもの、青がAIである。この時点ではまだまだゲームAIらしい動きができていない。
次に、学習の際の’Average Reward’が一番高く、評価フェーズで’no5’を選択した回数が一番多かった72回目のモデルとゲームをした際のモデルの挙動を表示する。
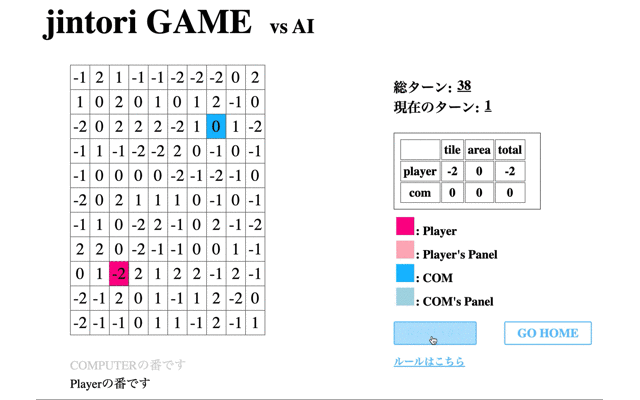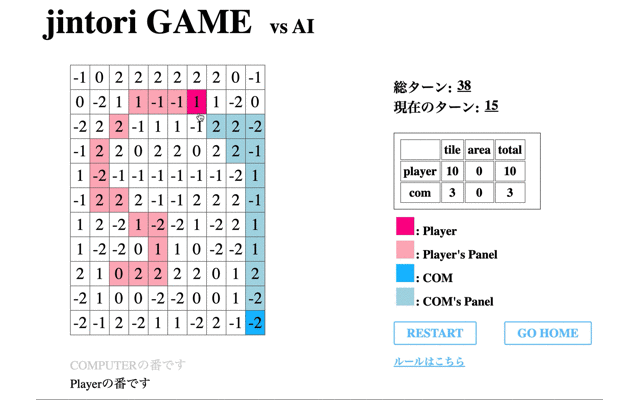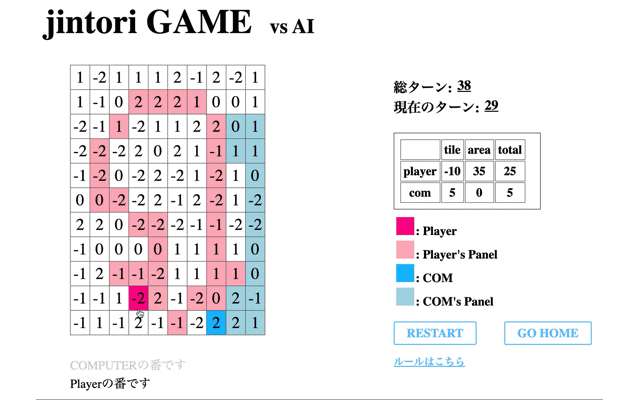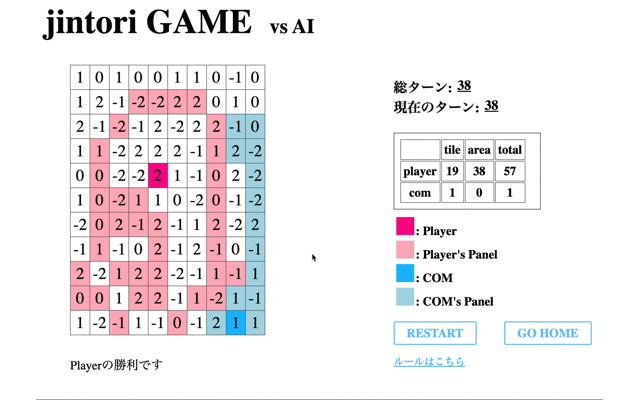
1回目の学習後よりある程度移動はするようになったものの、途中で止まってしまう(フィールド外への行動か相手パネルがないマスに対して削除を選択)、AIが相手にタイルで囲まれると削除せず動けなくなる、といったことがわかる。
つまり、移動に関しては学習が進んでいるもののパネル除去に関しての学習が進んでいないといえる。
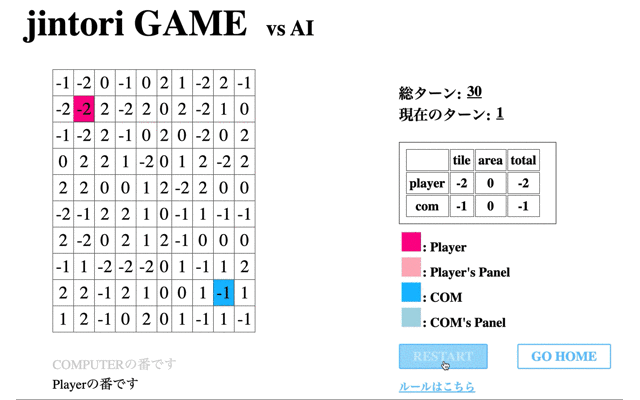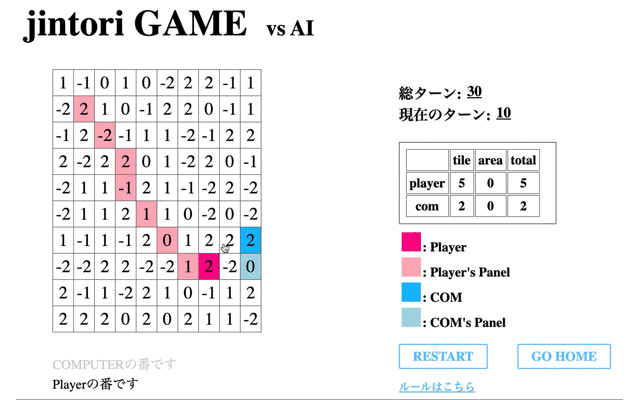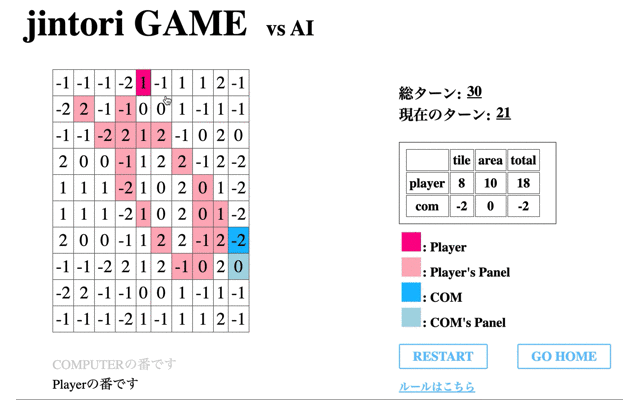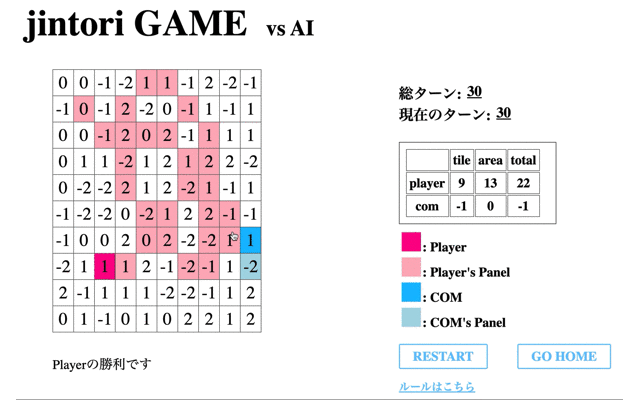
そして学習を全て終えたAIの挙動を表示する。先のCodeに関する結果からも併せると、ルールに従わない行動を選択することが多く正しく学習ができていないことがわかる。
検証1で学習がうまくいかなかった要因として考えられるのは、以下が挙げられる。
- 報酬設計
- 特徴量の設計
- ハイパラメータ周り
- ランダム要素が多い
- 学習回数が少ない
- 学習時の対戦相手
この中からいくつか変更を加え、検証2を行う。
検証2
この検証2では「ランダム要素が多い」、「学習回数が少ない」、「学習時の対戦相手」に問題があると考え、それぞれを変更した。
まず、「ランダム要素が多い」ということに関しては、試合のターン数、フィールドのサイズをそれぞれ45,9×9と固定化し、ランダム要素を初期位置の配置と、毎ターンでのタイルポイントのシャッフルのみとした。
そして学習回数は以下に示すように、学習と評価のセット数を200とした。
また「学習時の対戦相手」は、ルールベースに基づくエージェントとした。
また「学習時の対戦相手」は、ルールベースに基づくエージェントとした。
学習の設定
特徴量設計
検証1と同じ
報酬設計
検証1と同じ
学習回数
EPOCHS = 100,
NUMBER_OF_SELFPLAY = 20,
NUMBER_OF_SETS = 200
学習時の対戦相手
学習の際はルールベースに基づく対戦相手とする。
評価時の対戦相手
初回は同じものを戦わせる。2回目以降は。それまでの学習で最もLossの中央値が小さいモデルを対戦相手と設定する。
学習結果
Lossの推移
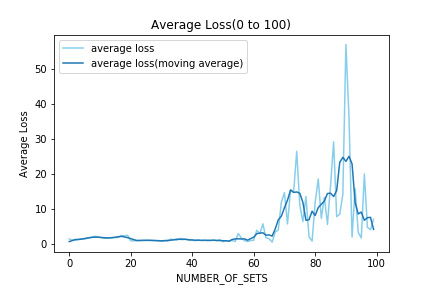
まず初回から100回目までのLossを示す。検証1と同様に学習を重ねるにつれてLossが増大していることが見られる。
また、検証1と比べLossが増大する時点が早くなっていることが見られる。しかし、100回目までのLossの最大値は検証1と比べて小さい値であった。
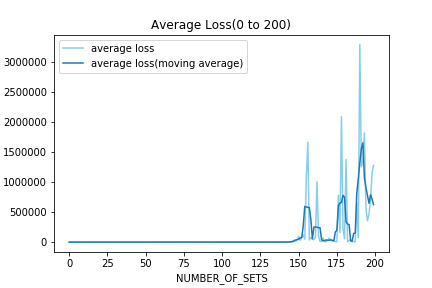
次に学習全体でのLossを示す。やはり100回目を超えてもLossが増大し続け、Lossの値が100回目までより遥かに大きな値をとった。
Rewardの評価
次に獲得Rewardについて評価する。まず、獲得Rewardをプロットしたものを表示する。
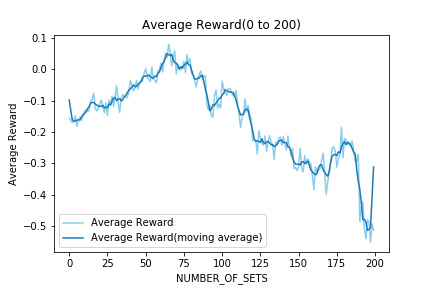
おおよそ60回目での獲得Rewardが最大値で、その後は減少に転じた。検証1と同様に、Lossが増大するにしたがって獲得Rewardも減少していることがわかる。
また、検証1での考察の際に「90回目を超えて減少したが再び増加しているから学習回数を増やして観察する」と書いたが、検証2でも同様にLossが増加し始めてからRewardが減少し、その後再び増加することが見られた。
しかし、それは短期的な増加であって全体的に見ると減少をしているものだとわかる。この獲得Rewardの結果から、闇雲に学習回数を増やせばいいとは限らないとわかった。
AIが陣取りゲームのルールを学習したか
検証1と同様にモデルがルール通りの動きをするか観察する。検証1と同様で、以下は評価フェーズでの結果である。
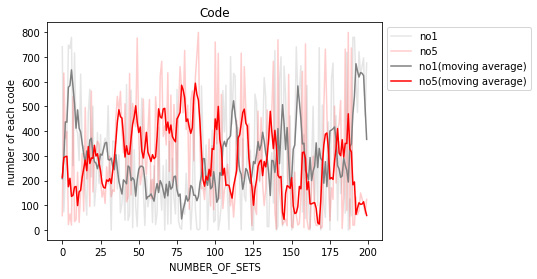
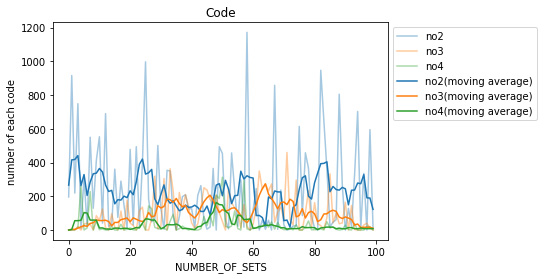
検証1と同様に100回目までは、no1は減少傾向で、no5は増加傾向であることが見れる。
しかし100回目を超えるとそれぞれの増加と減少の関係が逆転し、200回目を迎えると、no1をとる回数がno5をとる回数を上回り、正しい学習ができていないことがわかる。
この結果により、no1とno5の回数が交差し始める100回で学習を打ち切っても良い、もしくはさらに学習を重ねる必要がある、という2つが考えられる。
しかし、先のLossやRewardの結果よりこれ以上学習回数を増加させることはまずは考えなくてもよいと思われる。それ以外にLossが増加する原因を探る方が良い。
さらにパネル除去、移動 、 停留の選択した回数を見る。学習回数が100回目までと、それ以降で区切って表示する。検証1と同様に、各評価フェーズで行った試合数の数(20)で平均をとっている。
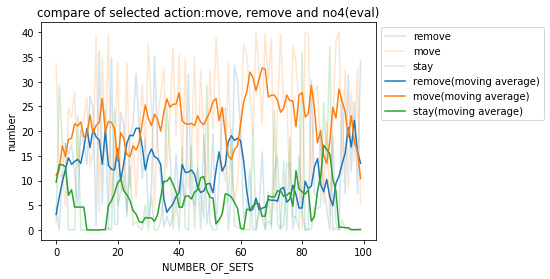
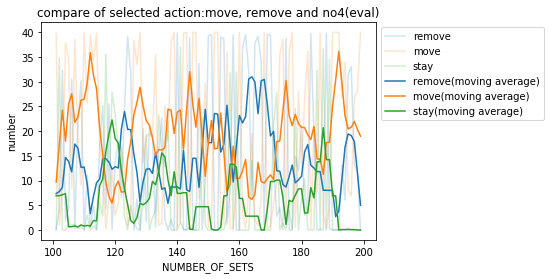
検証1と比べると、移動とパネル除去、停滞での差が大きくなく、どの行動も同じように選択していることがわかる。
しかし、100回目までは移動がパネル除去を上回っていたが、100回目以降はパネル除去と移動をとる回数が交差しており、パネル除去をとるということも学習されたと見られる。
取得ポイント
次に評価フェーズで学習済みAIが取得したポイントをプロットする。
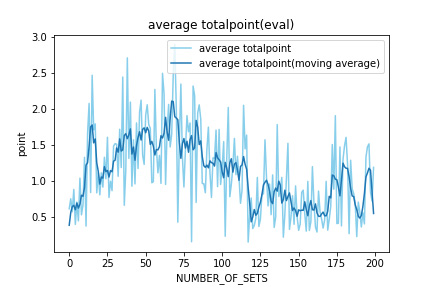
検証1と比べ、試合で取得するポイントの改善は見られない。また、学習回数が100回を超えると得点も減少している。やはり、先のLossやReward、Codeの結果から100回目以降はうまく学習が進んでいないと考えられる。
学習済みモデルの挙動
最後に学習済みモデルと戦った際の挙動を表示する。はじめに、1回の学習フェーズを終えたモデルの挙動を表示する。
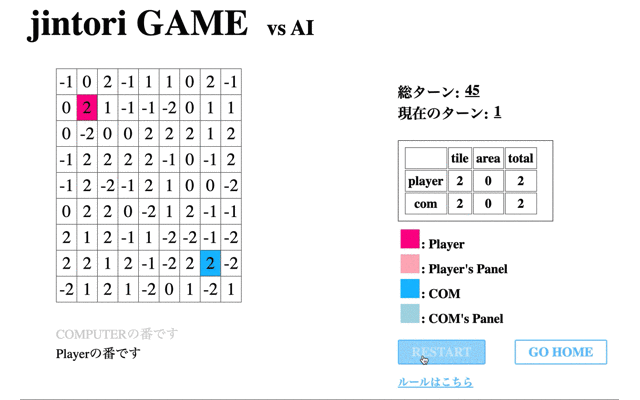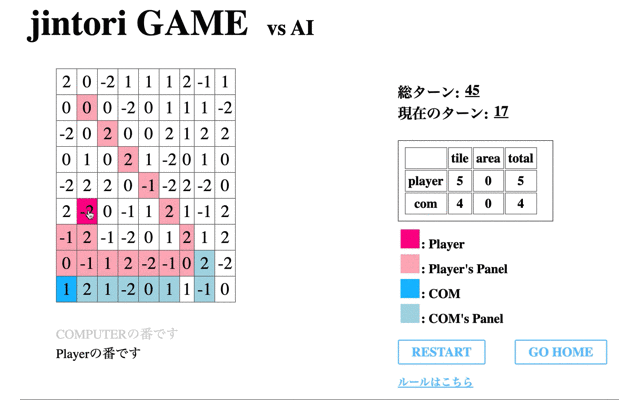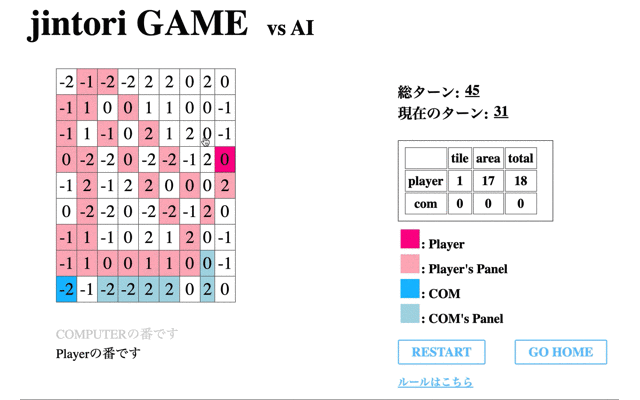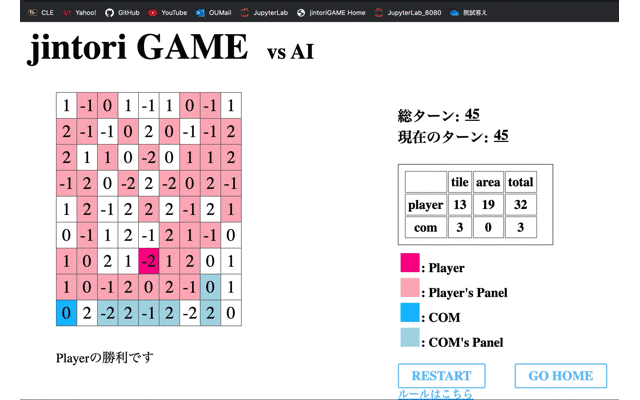
続いて、獲得Rewardが最大値を取った65回目のモデルと対戦した結果である。
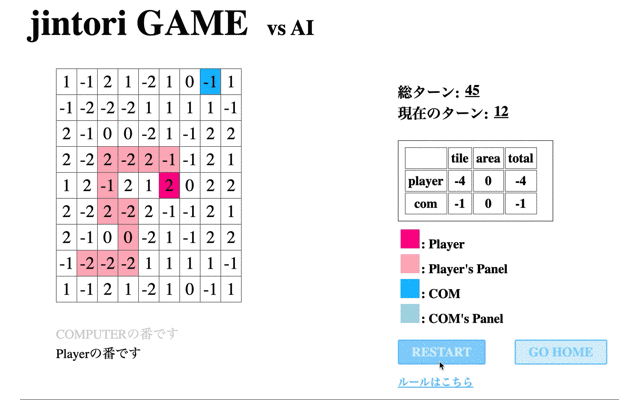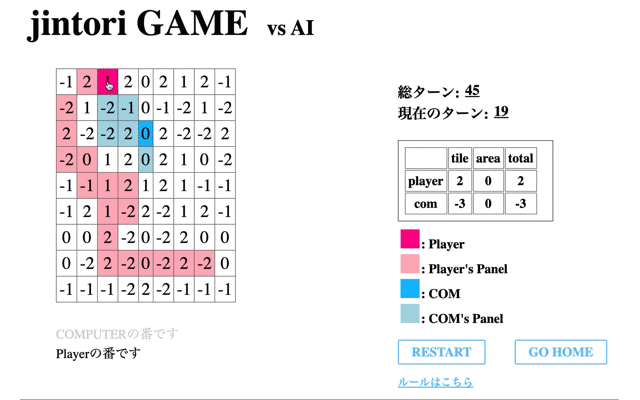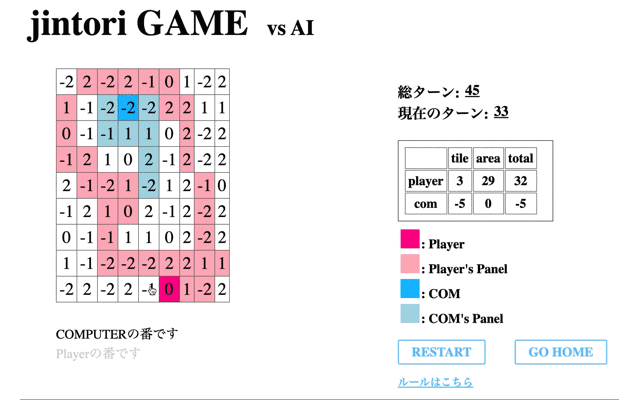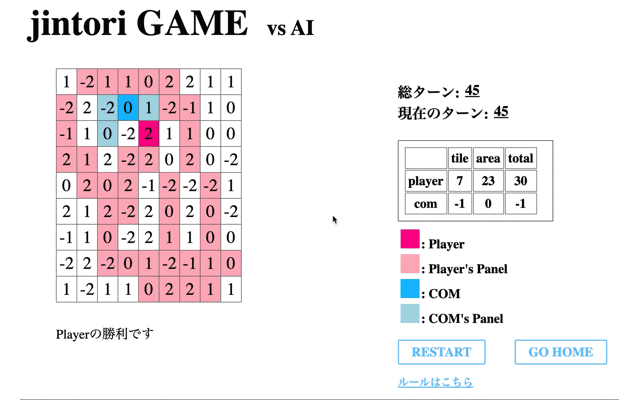
自分が過去に移動したマス内を動き回り、また相手パネルの除去もできていない。
次に,100回目のモデルとの対戦結果である。
はじめの数ターンは移動するが、角に移動するとそれ以上移動や削除ができていない。
最後に200回学習を終えたモデルと対戦した結果である。
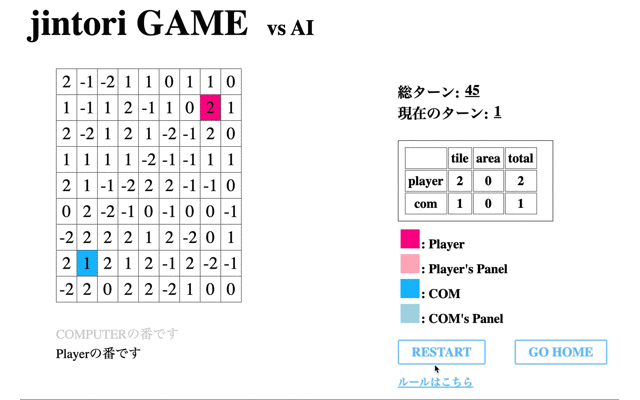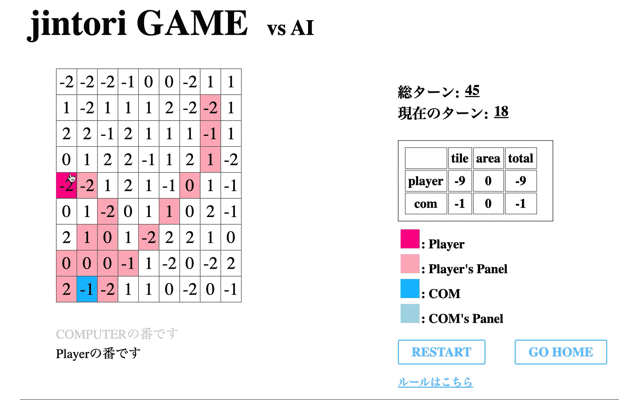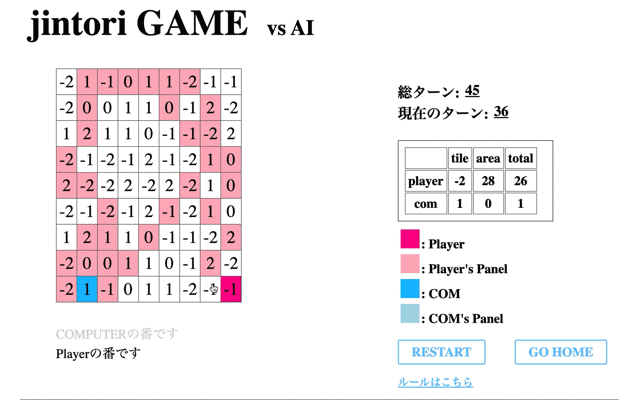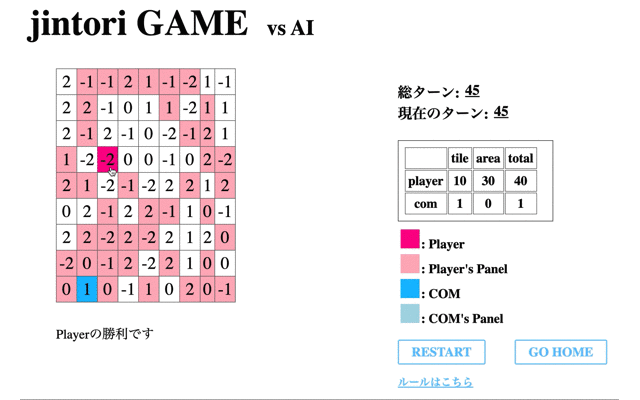
先のCodeに関する結果からもわかるように、一度移動してからは移動も削除もできていないことがわかる。
考察
以上から、検証1と同様にゲームAIのような学習はできていない。特に相手に囲まれると、パネル除去を選択せず先に進むことがないことが見られる。
また、検証2の際に変更した学習回数に関しては、学習の改善に大きな影響を与えられなかったと考えられる。
理由は、学習回数については増やしていった際にLossやRewardがそれぞれ増大、減少したからであり、それぞれ減少、増大をさせることができなかったからである。
対して対戦相手の変更に関しては、グラフ上では検証1と比べてモデルがパネル除去、移動、停滞を選ぶ回数に差が生まれなかったから、学習に影響が与えられたと考えられる。
ランダム要素の変更に関しては、検証1と同様にフィールドの端に移動すると動かなくなったということから、改善の役には立たなかったと考えられる。
まとめと今後の課題
以上の結果より、2020/5/21(木)時点で陣取りゲームを用いたDQNの学習はうまくいかなかったといえる。なぜなら、検証1と2を通じて
- 学習を重ねるにしたがってLossが増大する
- 学習を重ねるにしたがってRewardの値が減少する
- Codeの各値をとる回数に改善が見られない(ルール通りの行動選択を行えない)
- 試合で取得するポイントが少なすぎる
ということが数値的な結果として得られたからである。またこれらに加え、実際に戦ってみて挙動を見た際、明らかにゲームAIらしい動きをしていないからである。
今後の課題としては、まずLossが増大する原因を探ることが最優先だと考えられる。理由はLossの増大にしたがって他の数値に変化が見られ学習に影響を与えているからである。
解決手段としては、学習の際に記録する数値の変更や工夫を行い統計的な解析ができるようにするということが挙げられる。また特徴量の改善、報酬の改善も必須である。
今回、特に相手のパネルに囲まれた際にパネル除去という選択ができず強制的に停滞させられることが目立ったため、特徴量の変更として自分の周辺に相手パネルがあることを具体的に表現することや、それと合わせて報酬設計も見直す必要がある。