
この論文は、ICLR 2019で会議論文としてレビューされていました。
Fan Yuanxiang
June 20th, 2019
イントロダクション
概要
本論文では、深層強化学習によってアリババというECサイトにおける動的価格設定問題をどのように解決するかを提案した。
強化学習を使うには、
- 「Cold start」の段階(学習が済んでいない段階)ではランダムな選択をするため、利益が出てこない
- 需要関数が未知である(問題による)
- 報酬の定義する
という3つの問題を解決すべき。
この研究では、
- エージェントは過去の販売データから事前学習することで「cold start」を解決した
- 異なる報酬関数を定義することで需要関数が未知であることを解決した
- 収益より利益のコンバージョン率の差分がより適切な報酬関数であることを発見した
また、連続的な行動区間/離散的な行動区間について実験した
方法論
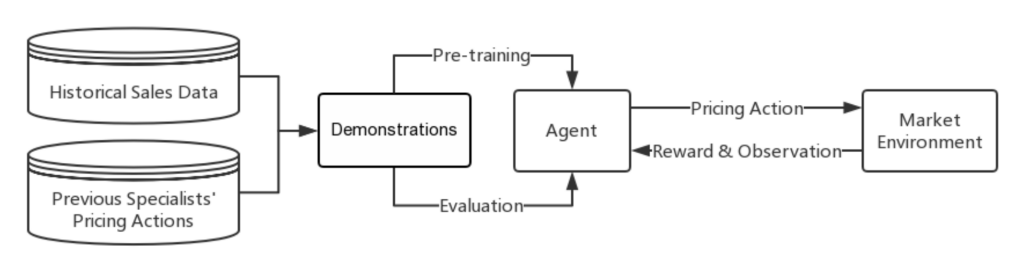
デモンストレーションデータは次の目的で使用される
- 事前学習
- オフライン評価
そしてこの論文で定義された問題は二種類がある
- 値下げ価格問題(供給は限られている)
- 商品が在庫切れの場合、価格エピソードは終了になる
- Fast moving custom goods (FMCG)設定の問題(供給は限られていない)
また問題をマルコフ決定過程としてモデリングする
製品のラベル \(i=1, 2, …, n\)
時間ステップ \(t=1, 2, …, T\)
各時間ステップ\(𝑡\)において、価格設定エージェントは商品の状態\(s_{i,t}\)を観察し、行動\(a_i,t\)を取る。次にエージェントが環境から行動\(a_{i,t}\)に対する報酬\(r_{i,t}\)と新しい状態\(s_{i,t+1}\)を受け取る。
時間ステップの決め方
- 環境の変化を表現するためには、一定期間の観察が必要である
- 短すぎるのはだめ
- 学習データが少ないと収益の最大化が報酬できないことを避ける
- 長すぎるのもだめ
本論文では時間ステップの長さは1日に設定されている。
状態スペース
状態\(s_{i,t}\)は4つの特徴によって記述されている
- 価格特徴(支払い情報、割引率、クーポン)
- 販売特徴(販売量、収益)
- 顧客アクセル特徴(PV、UV、購入者数)
- 競争力特徴(コメント、類似製品の情報)
行動区間
行動区間は商品ごとに別々に定義され、上限値\(P_i,_{max}\)と下限値\(P_i,_{min}\)は一定期間内の過去のデータの最大値と最小値によって決まる。
また、行動空間は異なる問題に対して連続的または離散的である。
- 行動空間が離散的な場合、行動は価格範囲で表現する
- 行動区間が連続的な場合、行動は価格で表現する
報酬関数
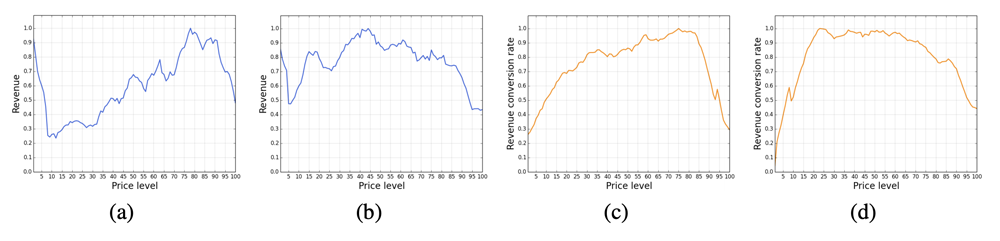
(c,d 収益コンバージョン)
収益コンバージョン\(r_{i,t} = revenue_{i,t}/uv_{i,t}\)は、報酬関数として使用される\(uv_{i,t}\)では時間ステップ\(t-1\)と時間ステップ\(𝑡\)の間の訪問者人数。
3か月以内の4800 SKUsのシャンプーと3300 SKUsの飴の収益と収益コンバージョンが価格によりの変化する画像を対比して、収益コンバージョンが収益より凸であることを示した。
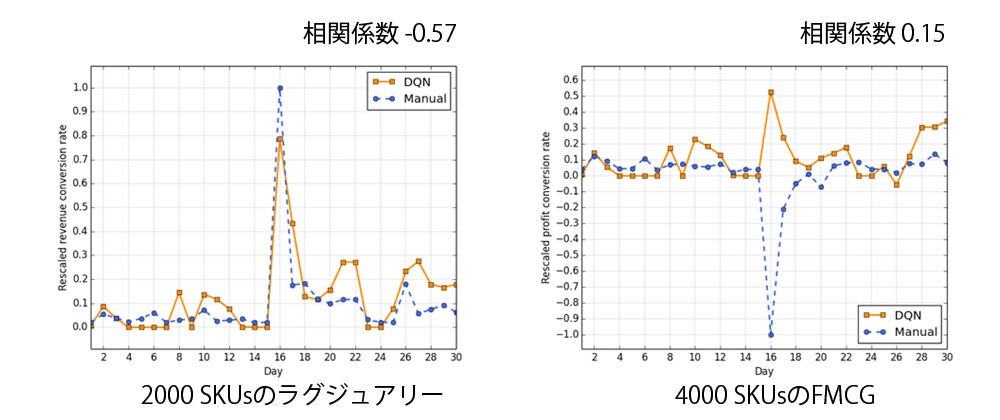
また、Fast moving custom goods (FMCG)とラグジュアリーの収益コンバージョン率が価格によりの変化を比較した。
ラグジュアリーでは25, 45, 65, 85のところ収益コンバージョンが上がることをわかる一方、FMCGでは、一定期間の価格と平均収益コンバージョンと価格の関係が不安定であることをわかっている。FMCGに対して報酬関数を以下のように定義。
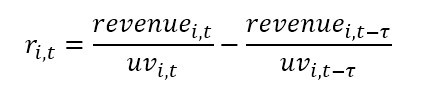
離散的な価格エージェント(DQN)
Q-Learningの更新式
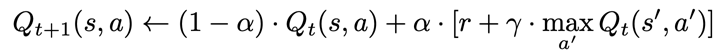
DQNの更新式(Lossを最小化)
Experience replayとSeparate target networkの手法が使用されている。
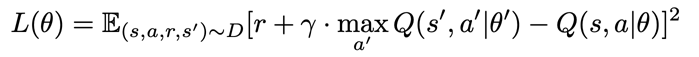
また、価格はK区間に分けられます。
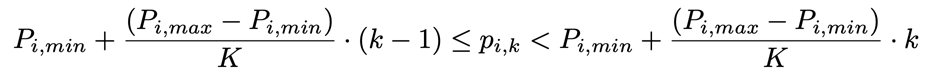
連続的な価格エージェント
問題は、Kが小さすぎると、広い価格帯は同じ価格と見なされる。一方、Kが大きすぎると、経験データに多くの行動が探索しなくなり、将来の探索も非効率的になる可能性がある。
この問題を解決するために、 本研究ではDeep deterministic policy gradient (DDPG)という方法を使った。

Loss function(with experience replay and separate target network):
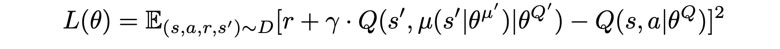
Criticに対して勾配を計算
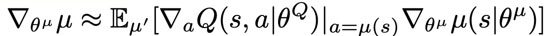
事前学習
強化学習アルゴリズムをECサイトのダイナミックプライシングに 直接適用すると、最初の段階ではパフォーマンスが非常に低くなり、「cold start」という問題が発生して、資本損失になる可能性がある。
事前学習することで、エージェントの行動方策がある程度スペシャリストの方策またはルールに従う可能性があり、価格決定がより合理的であるDeep Learning from Demonstration (DQfD)という手法を利用することで、事前学習が可能になる。
デモンストレーションデータの構成
\[<s_t,a_t,r_t,s_{t+1}>\]オフライン評価方法

誤差の定義
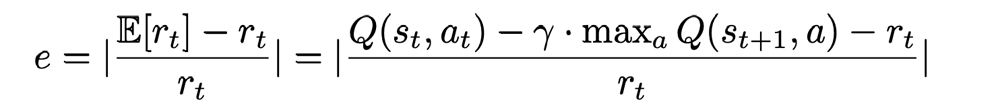
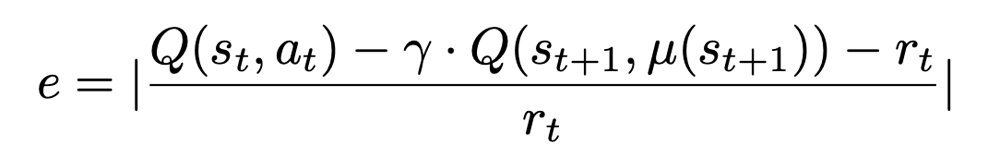
オフライン実験
本論文では、60日間の4万SKUのFMCGの記録を使ってオフライン実験を行った。最初の59日の記録をデモンストレーションデータとしてエージェントを事前学習させ、最後の日の記録を検証データとして評価する。
実験の結果として、DDPGは一定数のデモンストレーションを使用して事前学習の後、DQNよりもパフォーマンスが優れていることを示している。
※詳しい結果はこの論文のAppendixの部分を参照してください。
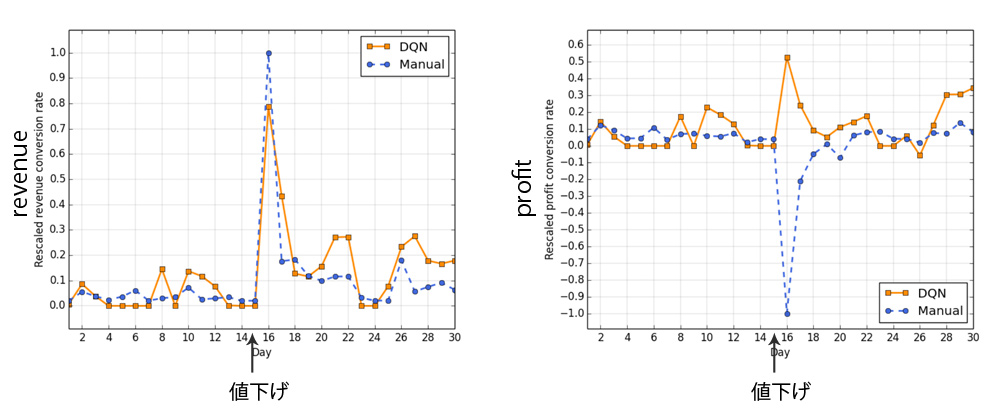
値下げ価格のオンライン実験
DDPGグループ、DQNグループおよびマニュアルグループを同じ期間に実験して比較した。(1000 SKUsのラグジュアリー)
- 1-15日目:普段の価格でDQNグループとマニアルグループの収益コンバージョン率が0.04、0.06
- •15-30日目:値下げ価格でDQNグループとマニアルグループの収益コンバージョン率が0.22、0.16
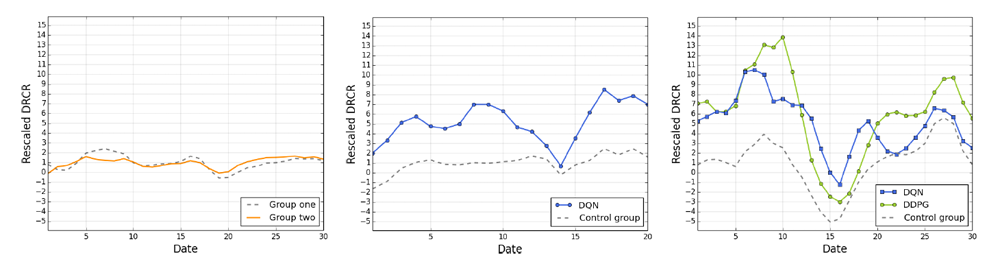
FMCGのオンライン実験
DDPGグループ、DQNグループとマニュアルグループを同じ期間に実験して比較した。(2000 SKUsのFMCG)
- 左:似てるFMCGが似てるDRCRであることを示している
- 中:20日間のDQNグループとコントロールグループの平均DRCRはそれぞれ5.24、1.00(rescaled)
- 右:30日間のDDPGグループ、DQNグループとコントロールグループの平均DRCRはそれぞれ6.07、5.03、1.00(rescaled)
Conclusion and Discussion
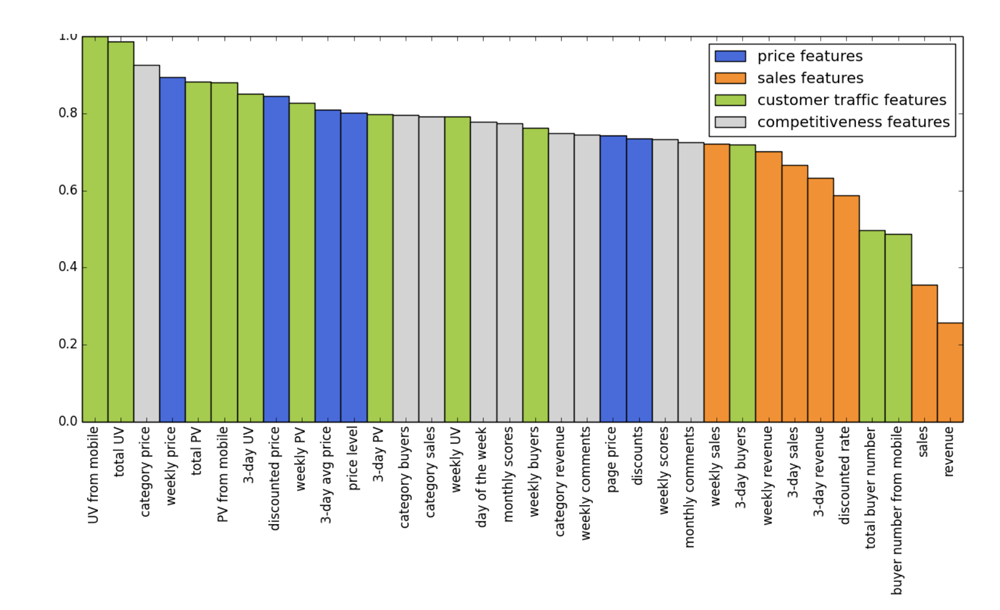
状態特徴の重さ
レビュー
メリット
- オンライン実験の結果が示している
- いくつかの特徴を状態として使っている( 価格特徴、販売特徴、顧客アクセル特徴、競争力特徴 )
- 価格が動作区間の下限と上限に制約されている
- 行動は継続的な行動空間に依存している
- 事前学習ができる
- 単なる収益の代わりに収益コンバージョン率を使用する
改善点
- この論文は新しい方法を紹介しておらず、よく知られている強化学習技術に頼っている
- 実験の実例と分析はさらに説明することができる
- 英語の文法やスタイル
深層強化学習
DQN
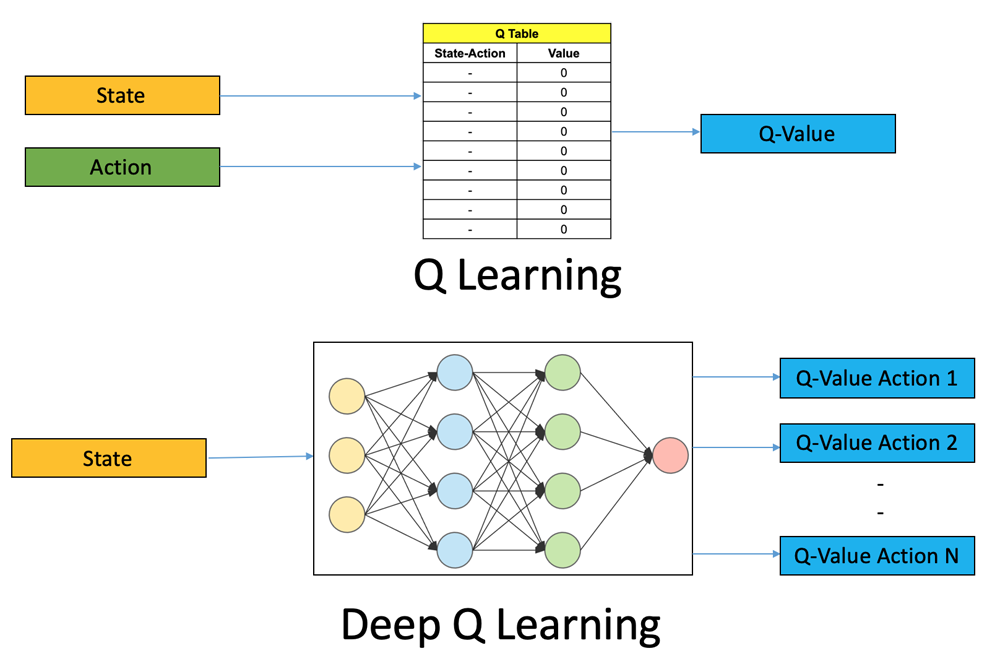
- 方策オフ型
- 状態は高次元になる可能性(Q-Learningと比較して)
- TD誤差により学習
引用元
https://zhuanlan.zhihu.com/sharerl
https://www.analyticsvidhya.com/blog/2019/04/introduction-deep-q-learning-python/
DDPG
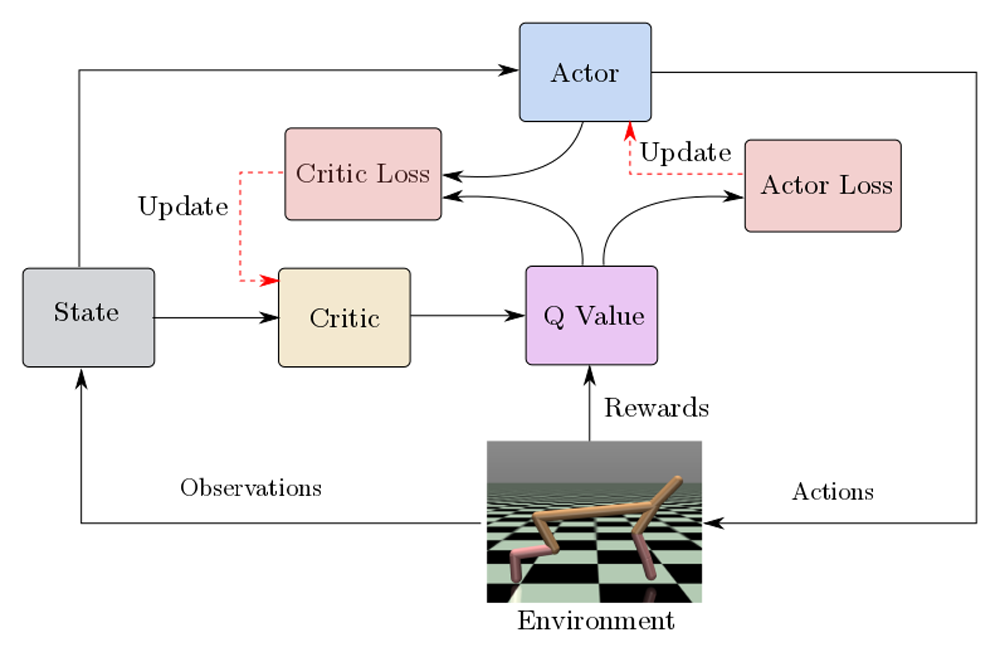
- 方策オフ型
- Actor-criticアルゴリズム
- 2つのニューラルネットワークを使用(ActorとCritic)
- TD誤差により学習
- 行動を連続的な行動空間から選ぶ
引用元
https://lilianweng.github.io/lil-log/2018/04/08/policy-gradient-algorithms.html#policy-gradient-algorithms
https://medium.com/@deshpandeshrinath/how-to-train-your-cheetah-with-deep-reinforcement-learning-14855518f916
事前学習
DQfD
DDQN Loss
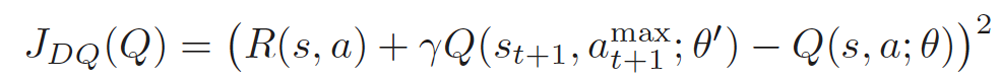
行動価値が一番大きな行動をとる
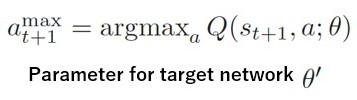
Supervisor Loss
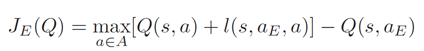
The action the expert demonstrator took \(a_E\)
Pretraining Loss
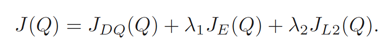

引用元
https://pdfs.semanticscholar.org/a7fb/199f85943b3fb6b5f7e9f1680b2e2a445cce.pdf