
Miyamoto
1 はじめに
今回の記事では、[1] を基盤として連続時間の強化学習(IRL)について取り扱います。
その名の通り、時間軸を離散ではなく連続でとらえるもので、\([0, T]\) 上で定義されます。
ですが当然連続のまま扱うことはできないので、まず連続で理論解析を行った後、それの離散化による実用化を目指します。連続的に考える応用数学はほぼすべてがこの立場です。
1.1 連続時間にするメリット
連続時間にすると、理論が難解になる上、離散化誤差等の考慮も必要となり、デメリットが目立ちます。それでもあえて連続で考える利点は、次のようなものが考えられます。
- 実態に即したモデルを作ることができる
- 時間刻み幅が等間隔でなくてよい
まず前者について、通常の強化学習では、環境は離散時間で遷移していると考えますが、ゲームAIのような非常に簡便な状況を覗いて、実際には連続時間でことは進んでいます。連続時間モデルで考えたほうが当てはまりがいいのは当然でしょう。
次に後者。これが一番大きいメリットではないかと思います。離散時間モデルを使う時、等間隔の時間に区切りをつけ、評価なり学習なりをしていかねばなりません。
一方連続時間モデルは、\(\Delta t_k = \Delta t_{k+1}\)である必要がなく、自由に刻み幅をとることができます。これは実応用の場では非常に大きい。\(^{\ast 1}\)
計算量増大は大したことないのですが、最大のデメリットは理論解析がめちゃくちゃ難しくなることです。SDE 使うのだから当然ですね。そのうちマリアヴァン解析出てくる。
SDE や強化学習の前提知識は一切解説しません。SDE の基礎の学習には例えば[2]などがおすすめです。
\(^{\ast 1}\)例えば弊社ソフトウェアthroough(スルー)では、値付けAI に対する強化学習において毎日決まった時間にネットワークの更新を行っていますが、連続時間モデルを導入すると\(\delta t, \delta B_t\)を適宜とれば良いだけになり、決まったタイミングでのパラメータ更新を行う必要がなくなります。
2 連続時間モデル概要
次のような二つの確率微分方程式を考えます。
(1)
\[d s_{t}=f^{\theta_{p}}\left(s_{t}, a_{t}\right) d t+g^{\theta_{p}}\left(s_{t}, a_{t}\right) d B_{t}\]
(2)
\[d a_{t}=\mu^{\theta_{v}}\left(s_{t}, a_{t}\right) d t+\sigma^{\theta_{v}}\left(s_{t}, a_{t}\right) d B_{t}^{\prime}\]
ただし、\(a_t, B_t \in \mathbb{R}^n \) \(s_t,B ^\prime _t \in \mathbb{R}^m\)とします。
各係数は適宜次元を合わせた可測関数で、結合した\(Y_t := (a_t, s_t)\)に関する\(n + m\)次元SDE
(3)
\[d Y_{t}=F^{\left(\theta_{p}, \theta_{v}\right)}\left(Y_{t}\right) d t+G^{\left(\theta_{p}, \theta_{v}\right)}\left(Y_{t}\right) d \bar{B}_{t}\]
を考えたとき、\(F,G\)には解の存在と一意性のためにリプシッツ条件と増大条件が成り立つものとします。ただし、
\(\bar{B}_{t}:=(B_t,B ^\prime _t)^{\ast 2}\)
現在、IRL の実用化における有力手法はモデルベース型です。\(\theta_p\)を最尤法で推定し、それを元に\(\theta_v\)を推定します。\(^{\ast 3}\)
\(^{\ast 2}\)これについても説明すると長くなるため、各SDEの資料参照。かなり基礎的な話なので、すべてのSDE入門の資料に間違いなく載ってます。ちなみに、\(f(x, y) := xy\)については、変数ごとにリプシッツ連続性が成り立ちますが、関数としてはリプシッツ連続ではありません。
\(^{\ast 3}\)SDE のパラメータの漸近正規性やそのための条件については広く研究されています。(中心極限定理リンク)
2.1 ベルマン方程式の連続化
state-action の連続化に伴い、ベルマン方程式も連続化する必要があります。
\(s _t\)に対して\(a_t\)の確率分布が\(\mu ,\sigma \)によって定まるわけですが、これをまとめて\(\pi (a_t | s_t)\)と書き、\(\mu , \sigma\)は略記します。
定義1 状態価値関数と最適方策
\(s_t\)は上記SDEに従うとし、それに対する行動は\(\pi\)で定まるとします。このとき、状態価値関数を次のように定義します。
(4)
\[V^{\pi}(s):=E\left[\int_{0}^{T} r_{t}\left(s_{t}, a_{t}\right) d t\right]\]
さらに、\(\Pi\)をリプシッツ条件と増大条件を満たす任意の \(\mu , \sigma\) とし、さらに時刻\(0\)での状態を\(s_0\) としたうえで最適方策を次のように定義します。
(5)
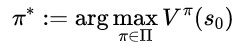
定義2 連続化ベルマン方程式
最適状態行動価値関数は、任意の\(t\)に対して次の等式を満たします。
(6)
\[Q^{*}(s, a)=E\left[\int_{0}^{t} \gamma^{h} r_{h}\left(s_{h}, a_{h}\right) d h+\gamma^{t} Q\left(s_{t}, a_{t}\right)\right]\]
このような\(Q\)は存在するでしょうか。その答えを出すために、まずは次の必要条件を考えます。
この値は\(t\)に拠っていてはいけないので、\(t\)での微分が\(0\)になる必要があります。
(7)
\[\frac{\partial}{\partial t} Q^{*}(s, a)=0\]
この解析は、昔ながらの古典的な伊藤拡散過程の議論から、ファインマンカッツの公式などに持ち込むことが可能です。
左辺を開いていきましょう。\(y=(s, a), Y_{t}=\left(s_{t}, a_{t}\right), q(y, t)=E^{\left(s_{0}, a_{0}\right)}\left[Q^{\theta^{*}}\left(Y_{t}\right)\right]\)
(8)
\[0=E^{(s, a)}\left[r_{t}\right]+| \log \gamma q(y, t)+\frac{\partial}{\partial t} q(y, t)\]
定義3 伊藤拡散過程の生成作用素
\(\mathbb{R}^d\)上の関数、\(f \in C^2\)であるとします。すなわち2 階連続微分可能です。伊藤拡散過程\(\{X_{t}\}_{t=0}^{\infty}\)に対する生成作用素\(A\)を次のように定義する。\(^{\ast 4}\)
\(^{\ast 4}\)超おおざっぱに言えば\(Ef(X_t)\)の時間微分です。正確な定義ではありませんが、大体そんなものという認識を持っていただければ。
(9)
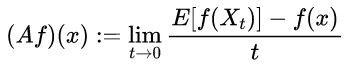
ただし、\(X_t\)は次のように表現できているものとする。
(10)
\[X_{t}^{x}=x+\int_{0}^{t} b\left(X_{s}\right) d s+\int_{0}^{t} \sigma\left(X_{s}\right) d B_{s}\]
また、\(\mathcal{A}\) は次のような同値な定義も存在します。基本的に使うのはこっちです。\(^{\ast 5}\)
\(^{\ast 5}\)伊藤の公式の形と非常に似ています。これは偶然ではなく本質的なつながりがあります。
(11)
\[\mathcal{A}=\sum_{i} b_{i}(x) \frac{\partial}{\partial x_{i}}+\frac{1}{2} \sum_{i, j}\left(\sigma \sigma^{T}\right)_{i, j}(x) \frac{\partial^{2}}{\partial x_{i} \partial x_{j}}\]
定理1 コルモゴロフの後退方程式
\(u\)を\(C^{1,2}\)級関数とし、次のような偏微分方程式を考えます。
(12)
\[\frac{\partial}{\partial t} u(t, x)=\mathcal{A} u\]
(13)
\[u(0,x) = f(x)\]
ただし、\(A\)は伊藤過程\(\{X_t\}_t\)の生成作用素であるとします。
これは初期値問題と言われます。このとき、
(14)
\[u(t, x)=E\left[f\left(X_{t}^{x}\right)\right]\]
ここから、ギルサノフの定理などを使った最尤法などが、論文で紹介されています。
3 最後に
前半記事はここまでです。読了いただき、誠にありがとうございます。
論文[1] の定義があまりよくなく、自力での再定義を試みたのですが、なかなかうまくいかなかったため、とりあえず前編という形で簡易まとめをアップロードさせていただきました。
後半記事では、POMDPのときと同じく独自再定義を行い、さらにそこから今後の研究課題について考察したいと思います。
SDE 型だと、分布型強化学習[3] のほうが遥かに扱いやすいと思われます。その辺の研究は多くの数学者によってかなり為されており、離散時間で決定論的なベルマン方程式等を考えるより、偉人達の蓄積を活用しやすいです。
また、論文ではかなり適当に扱われている\(r_t\)を、飛躍型確率微分方程式を使って定式化できないかと考えています。\(^{\ast 6}\)
論文[1] では最尤法などで定式化が行われ、漸近正規性などの考察が行われていますが、ここはやはり通常の強化 学習に倣って、ベルマン作用素で最適化していくべきだと思われます。 \(^{\ast 7}\)
また、分布型にすることで、エルゴード性の議論[4]に持ち込むことができ、より楽に解析することができます。
\(^{\ast 6}\)各点独立な確率超過程や、普通のSDE で定式化することもできますが、弊社のダイナミックプライシングや自動運転やロボットといった、実社会に強化学習が使われている場面では、ポアソンモデル的に報酬を捉える。(つまり飛躍型確率微分方程式で考える)のが最も自然ではないかと思われます。
\(^{\ast 7}\)連続時間なのでベルマン半群と呼ぶべきでしょう。
参考文献
[1] Tianhao Chen, Limei Cheng, Yang Liu, Wenchuan Jia and Shugen Ma, Fellow, Incremental Reinforcement Learning a New,Continuous Reinforcement Learning Frame Based on Stochastic Differential Equation
methods , IEEE 2018
[2] 舟木直久, 確率微分方程式. 岩波オンデマンドブックス(2004)
[3] Mark Rowland,Marc G.Bellemare,Will Dabney,Remi Munos,Yee Whye Teh,An Analysis of Categorical Distributional Reinforcement Learning,arxiv:1802.08163,2018
[4] A. Yu. Veretennikov , On