
kanou
はじめに
今回は強化学習の⼿法DQN(Deep Q Network)を使ってゲームAI をつくり、強化学習がどのようなものなのかを説明したいと思います。
DQN についての詳細な説明に関しては下記のリンクを参照してもらえればと思います。
ゲームの説明
今回のゲームはこのゲームを参考にして作らせていただきました。
https://github.com/JulesVerny/PongReinforcementLearning
ゲームのルール

このゲームは卓球のようにボールを板ではね返していくゲームです。
相⼿はボールの動きから必ずボールを打ち返せるように設定されています。⾃分がボールを打ち返すことが出来ればポイントが+10 点、ボールを打ち返すことができずに⾒送ってしまったら−10 点です。
ゲームの複雑性を増すために参考にしたコード中間に2枚の上下にランダムな速度で動く壁を追加しました(以下これをランダムな壁と呼ぶ)。
ランダムな壁がないとボールは位置によって進む経路が決まってしまいますが、今回はランダムな壁を加えてボールがある程度予測できない動きをするような設計にしました。
モデルの説明
状態の観測
状態として、⾃分の位置、ボールの位置、ボールX ⽅向とY ⽅向に進む向き、2枚のランダムな壁の位置の合計6個のデータを観測してそれぞれ0 以上1以下に正規化し、⼊⼒としました。
行動
モデルの⾏動は上に移動、下に移動、停⽌の3種類です。
⾏動の選択にはε-greedy 法を採⽤しました。ε-greedy 法についての詳細はここではしませんが、簡単に⾔うと学習の初期段階ではランダムに⾏動をとって様々な⾏動を試し、徐々にモデル⾃⾝の決定を⾏っていく⾏動探索⽅法です。
報酬
ゲームのポイントと同じくボールを打ち返すと10,ボールを打ち返せずに⾒送ってしまったら-10,そのほかの場合は0と設定しました。
学習
学習は過去2000 回分のデータからランダムに取得してゲームが動くごとに学習することにしました。
他にも、学習をゲームの勝敗が決まるごとに学習を⾏ったり、⼊⼒データを勝敗のついた⼀連のゲーム分をまとめてモデルに⼊⼒したり試⾏錯誤しましたが、結局この⽅法の結果が⼀番よかったです。
学習の様⼦
実際の学習の様⼦です。ゲームの勝敗がどうなったかわかりやすくするためにボールの⾊を勝利したら⻘、敗北したら⾚に変えています。
最初はボールを打ち返すことが難しくボールが⾚⾊に変化することが多いですが、モデルが徐々にボールを打ち返し始めるのがわかると思います。
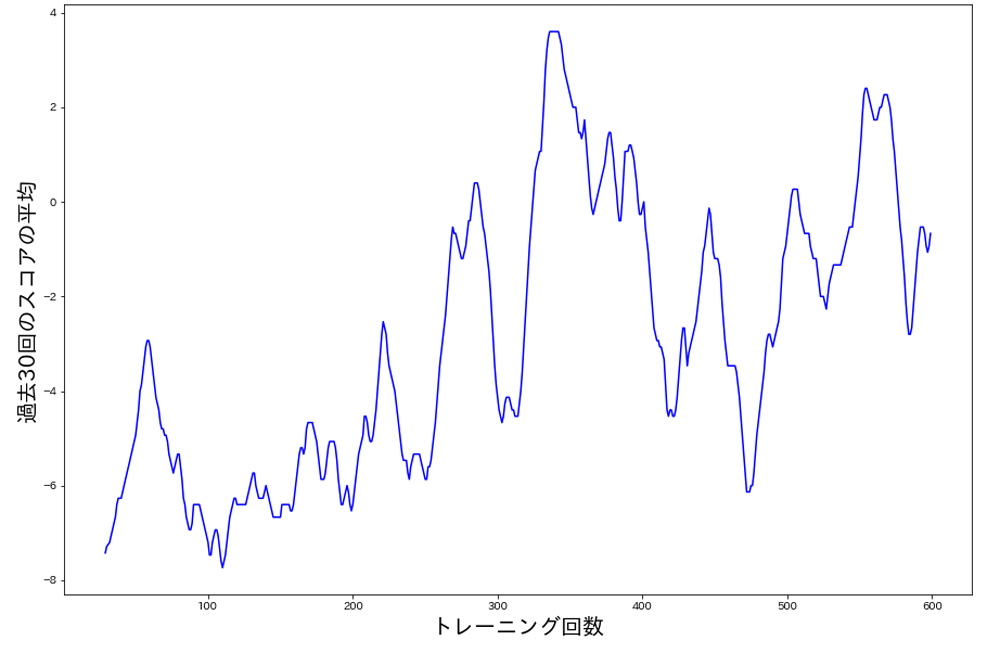
結果をグラフ化すると以下のようになりました。横軸はモデルの訓練回数、縦軸は過去30回のスコアの平均をとったものになっています。
楽観的初期化
楽観的初期化というのはモデルを学習開始の前に全ての⾏動を均等にとるように設定することで、学習初期にモデルが多様な⾏動を試し効率よく学習を進められる⽅法です。
これはダイナミックプライシングツールthroough(スルー)のアルゴリズムにも導⼊しています。
今回はこの⽅法も試してみることにしました。実際の学習の様⼦です。
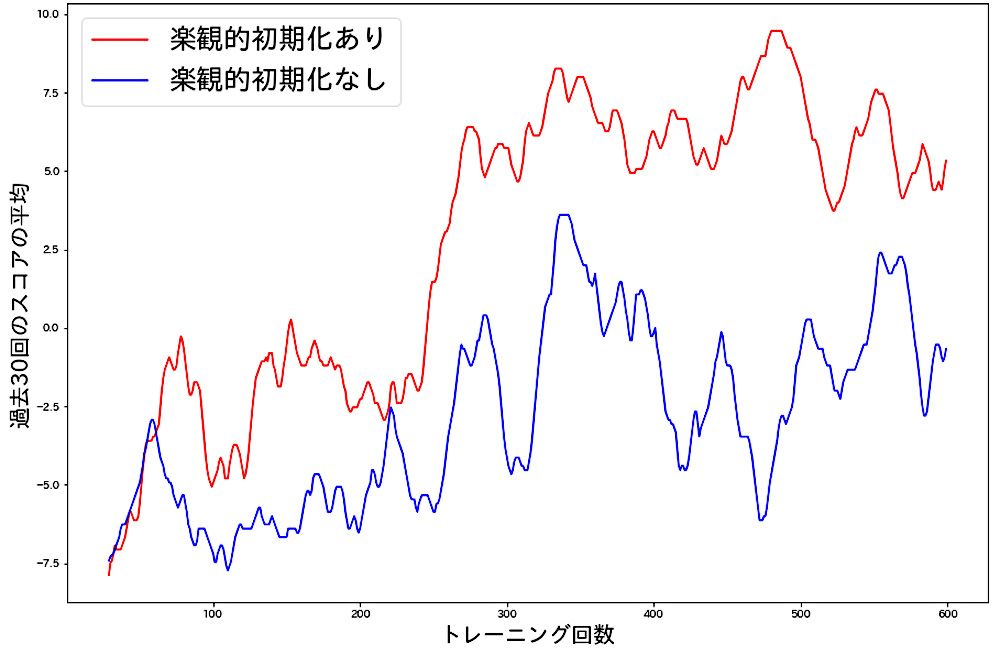
通常の場合と楽観的初期化の場合を⽐べるとこのようになりました。
⾚線が楽観的初期化あり、⻘線が楽観的初期化なしの結果になります。明らかに楽観的初期化を⾏なった⽅が、結果が良いことがわかります。
最後に楽観的初期化を⾏ったモデルのまとめの動画を載せて終わりたいと思います。ありがとうございました。